Vector Databases
Vector databases are a critical component of RAG (Retrieval-Augmented Generation) pipelines in Vectorize. They store and index vector embeddings, enabling efficient similarity searches crucial for retrieval operations.
What are Vector Databases?
Vector databases are specialized storage systems designed to handle high-dimensional vector data. In the context of RAG pipelines, they store the vector representations of your documents, allowing for quick and efficient similarity searches when retrieving relevant information.
Available Vector Database Integrations
Vectorize supports several vector database integrations to suit different needs and preferences:
- Built-In Vector Database: Vectorize's built-in vector database for quick and easy setup.
- Astra DB: DataStax's cloud-native Cassandra-based vector database.
- Azure AI Search: Microsoft's AI-powered information retrieval platform.
- Couchbase Capella: Couchbase's fully managed NoSQL database with vector search capabilities.
- Elastic Cloud: Elasticsearch's cloud offering with vector search functionality.
- Milvus: Milvus open source or Zilliz cloud vector database
- Pinecone: Purpose-built vector database for machine learning and AI applications.
- PostgreSQL: PostgreSQL with vector support using pgVector.
- Supabase: Supabase with PostgreSQL and pgVector for beginners.
- SingleStore: SingleStore general purpose database with vector support.
- Turbopuffer: Turbopuffer's vector database for fast and scalable vector search.
- Qdrant: Open-source vector database with advanced similarity search capabilities.
- Weaviate: Weaviate's knowledge graph database with vector search capabilities.
Configuring Vector Database Integrations
You can configure vector database integrations in two ways:
1. From the Vector Databases Section
-
Navigate to the Vectorize dashboard.
-
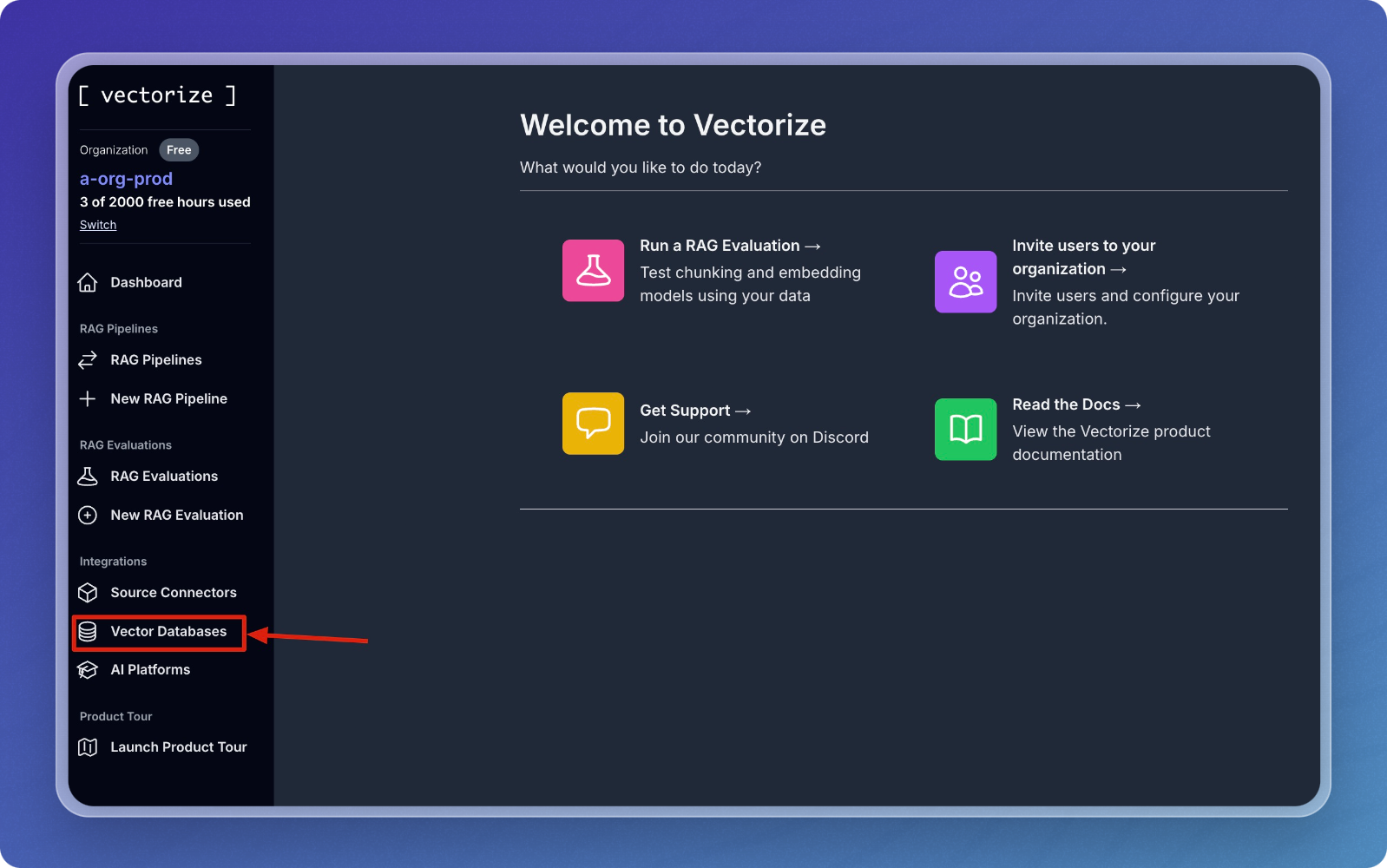
In the left sidebar, under "Integrations," click on "Vector Databases."
-
You'll see a list of currently configured vector database integrations in your workspace.
-
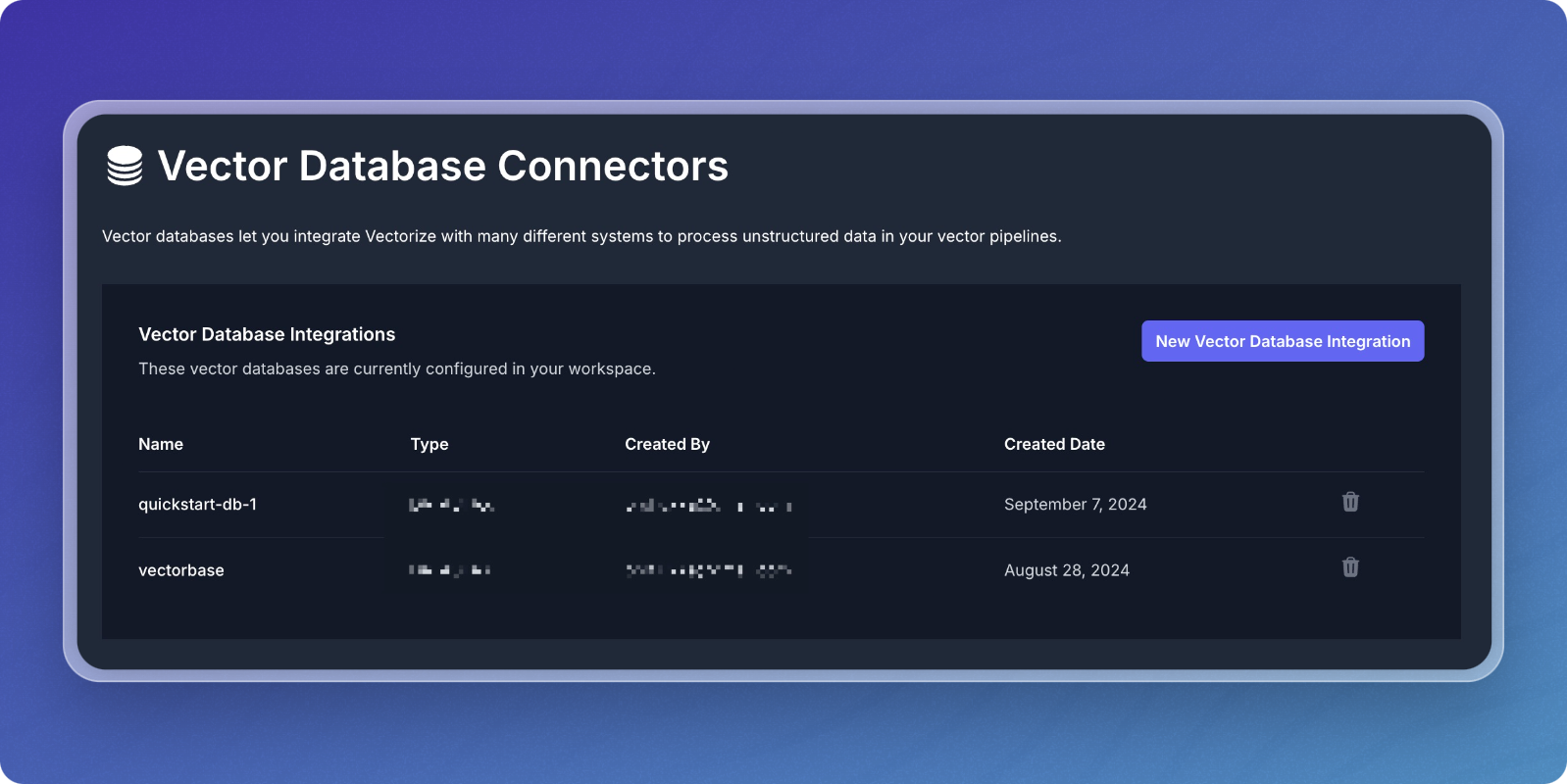
To add a new integration, click the "New Vector Database" button.
-
Choose from the list of available vector database options.
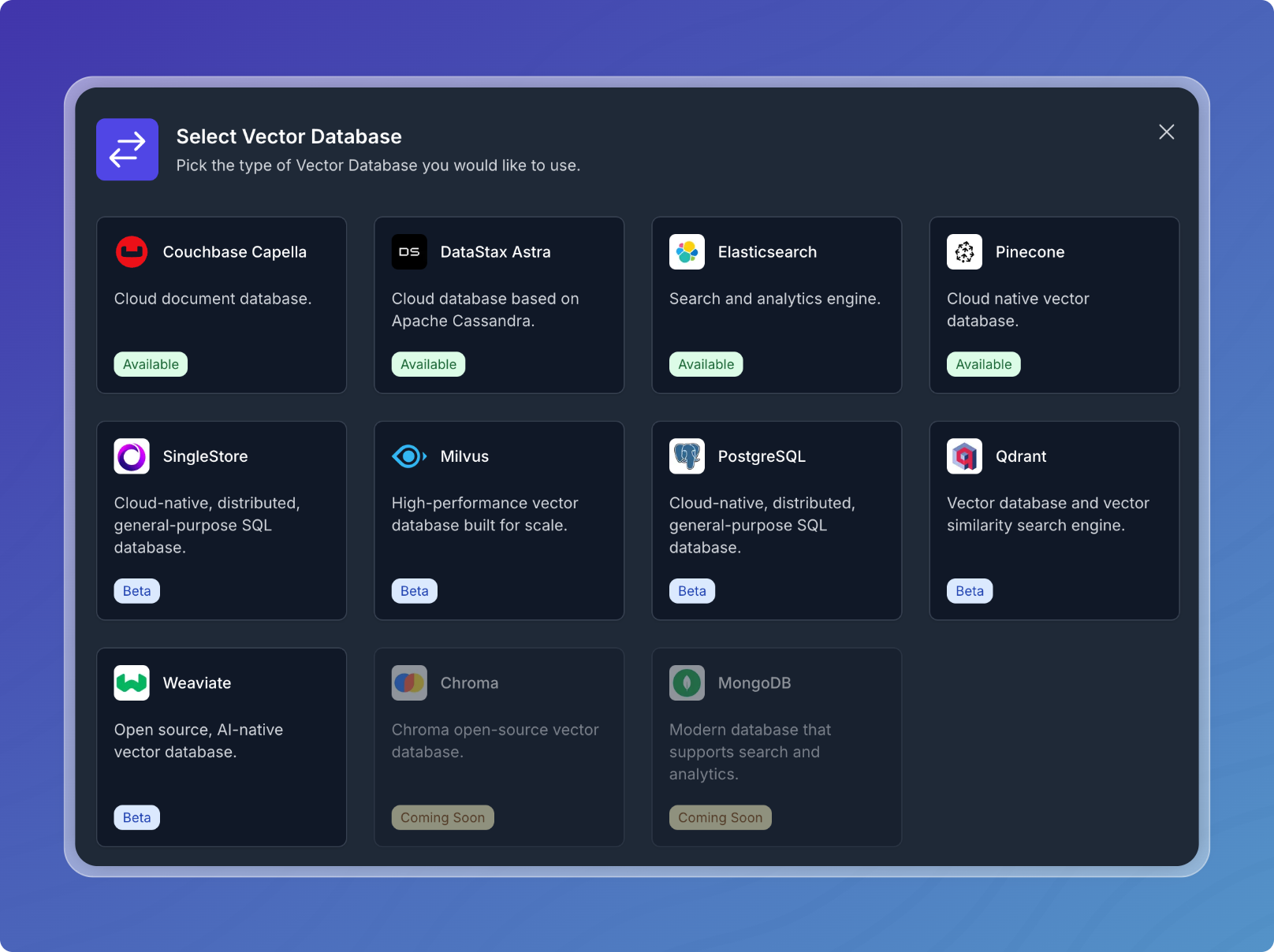
- Follow the prompts to configure the selected vector database integration.
2. While Creating a RAG Pipeline
-
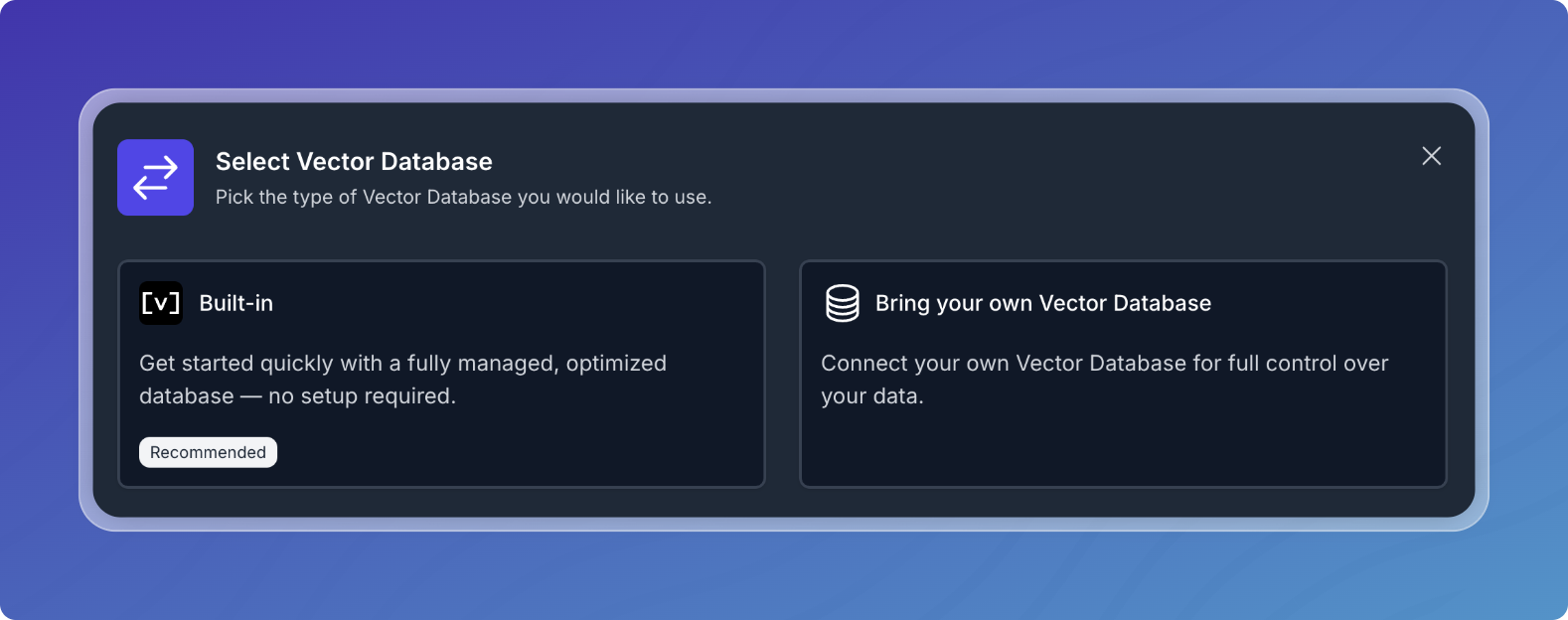
When configuring a new RAG pipeline you can choose between a built-in or bring your own vector database. Bring your own is useful when you want to use a vector database outside of Vectorize.
-
If you select your own database, you also have the option of creating a new integration. Choose from the available options and follow the configuration steps.
Note: Vector database integrations configured as part of a RAG Pipeline will automatically appear in the Vector Databases list for your organization and can be reused in future RAG pipelines.
Configuration Details
When setting up a vector database integration, you'll typically need to provide:
- Connection details (e.g., endpoint URL, region)
- Authentication credentials (e.g., API keys, access tokens)
- Index or collection name
- Any specific configuration options for the chosen database
For detailed information on configuring specific vector database integrations, please refer to their individual documentation pages linked above.