Updates
2025-09-20
External MCP Tools Support for Chat Agents
Chat agents (Chat Apps and Chat Widgets) can now connect to external MCP (Model Context Protocol) servers to access third-party tools and integrations. This enables Chat agents to perform actions beyond retrieval, such as creating Linear issues, managing GitHub repositories, or integrating with custom business systems. External tools support multiple authentication methods including Bearer tokens, OAuth 2.1 with dynamic client registration, and custom headers. Learn more about external MCP tools.
2025-09-05
Hybrid Retrieval and Advanced Filtering
Vectorize now offers three retrieval modes for the built-in database and Elasticsearch:
- Vector Search - Pure semantic similarity for conceptual queries
- Text Search - Exact keyword matching for specific codes, terms, or phrases
- Hybrid Search - Combines semantic understanding with keyword precision
Advanced filtering capabilities include:
- Boolean combinations (AND, OR, NOT)
- Range queries for dates, numbers, and priorities
- Nested conditions (e.g., "Q3 2024 docs that are either high-priority OR finance, but not drafts")
Example use case: Search for "revenue guidance" while filtering for the exact term "Q3" to find documents that are both conceptually relevant and textually precise. Learn more about advanced queries.
2025-09-02
Chat Agents
New agent types for deploying AI assistants: Chat Apps (standalone applications) and Chat Widgets (embeddable components). Features include multi-model support, authentication, admin panel, and customizable branding. Chat Agents Overview.
Remote MCP Agent Integrations
MCP agents now remotely integrate with popular AI development tools including Claude Desktop, Claude Code, Cursor IDE, Groq Desktop, OpenAI Playground, and Warp AI. View all integrations.
Real-time Pipelines
Pipelines can now synchronize in real-time with source data changes. When documents are updated in connected sources, embeddings are automatically refreshed without manual intervention. Learn more about real-time pipelines.
2025-06-26
Advanced Queries on Built-In Database and Elasticsearch
The built-in database and Elasticsearch now supports advanced metadata filtering with a rich set of operators and multiple clauses. It also supports hybrid and full-text search modes. Learn more about advanced queries
Improved Source Events
Source connectors now emit details pipeline events that indicate their operations, such as connecting to the API, the number of documents discovered, and the end of processing cycle.
2025-06-16
Light Mode
For those that that want to see the light, we have added light mode to our web application. Just click on the icon at the bottom left of the page to toggle between light and dark mode.
2025-06-12
Turbopuffer Vector Database Integration
We've added support for the Turbopuffer vector database. Quickly populate your Turbopuffer cloud namespace using Vectorize pipelines. Learn more about the Turbopuffer integration.
2025-06-05
Google Drive Shared Drives and Folders
Our Google Drive connectors can now read files in shared folders and shared drives.
Notion Multi-Tenant OAuth
We've added OAuth support for Notion, including multi-tenant options using Vectorize permissions or white-label permissions. Now your end users can give permission to connect their Notion resources to a data pipeline.
2025-05-27
Fireflies.ai Connector
Pull all your meeting transcripts from Fireflies.ai into your data pipelines. Learn more about the Fireflies.ai integration.
2025-04-30
Automatic Metadata Extraction
We've added automatic metadata extraction capabilities that allow you to define schemas for extracting structured information from your documents. This powerful feature uses our Iris model to analyze documents and extract both document-level and section-level metadata, enhancing your retrieval capabilities with additional context and filtering options. Learn more about Automatic Metadata Extraction.
Visual Schema Editor
The new visual schema editor makes it easy to define and manage metadata schemas without needing to write JSON directly. You can start from scratch, use pre-defined templates, or have the system automatically generate a schema by analyzing your documents. Learn more about creating metadata schemas.
Enhanced Retrieval with Metadata
Improve retrieval quality by adding extracted metadata to your text chunks. This feature makes important information available during semantic search, especially beneficial for documents that span many chunks or contain specific value strings. Learn more about metadata settings.
2025-04-24
Dropbox Multi-tenant OAuth
We've added OAuth support for Dropbox, including multi-tenant options using Vectorize permissions or white-label permissions. Now your end users can give permission to connect Dropbox to a data pipeline. Learn more about Dropbox OAuth support.
2025-04-09
Google Drive OAuth
We've added OAuth support for Google Drive, making it easier to connect and ingest data from your Google Drive documents. Learn more about Google Drive OAuth.
Chunk Metadata Improvements
Enhanced chunk metadata now includes page start/end information, making it easier to trace chunks back to their original document pages. Learn more.
Overages Spend Limit Management
Added improved overages spend limit management features, including better visibility of thresholds and clearer messages when limits are reached. Learn more about spending limits.
2025-03-14
Pipeline Editing Improvements
We've enhanced our pipeline editing capabilities, allowing you to modify existing pipelines without having to recreate them. You can now edit pipeline names directly from the pipeline view, add new data sources, change extraction techniques, and make other modifications to your data pipelines, making it simpler to organize and manage your data processing workflows.
2025-03-04
Deep Research
We've added the ability to do deep research on your private data. Using the data in your pipeline, our deep research feature will generate a report on any topic. You can combine your private data with internet data using the web search and you can save the report as a PDF when it is done. You can specify exactly how you want the report to be structured, or you can let deep research figure it out.
2025-02-24
Built-in Vectorize Database & Embedder
We've added a built-in vector database and embedder, allowing you to get your data pipeline up and running without needing to set up a separate vector database. You can still use your own database if preferred.
Interactive Pipeline Tour
The pipeline tour now not only walks you through the steps of creating a pipeline and retrieving data, but also creates a pipeline for you in real-time using the built-in vector database and embedder.
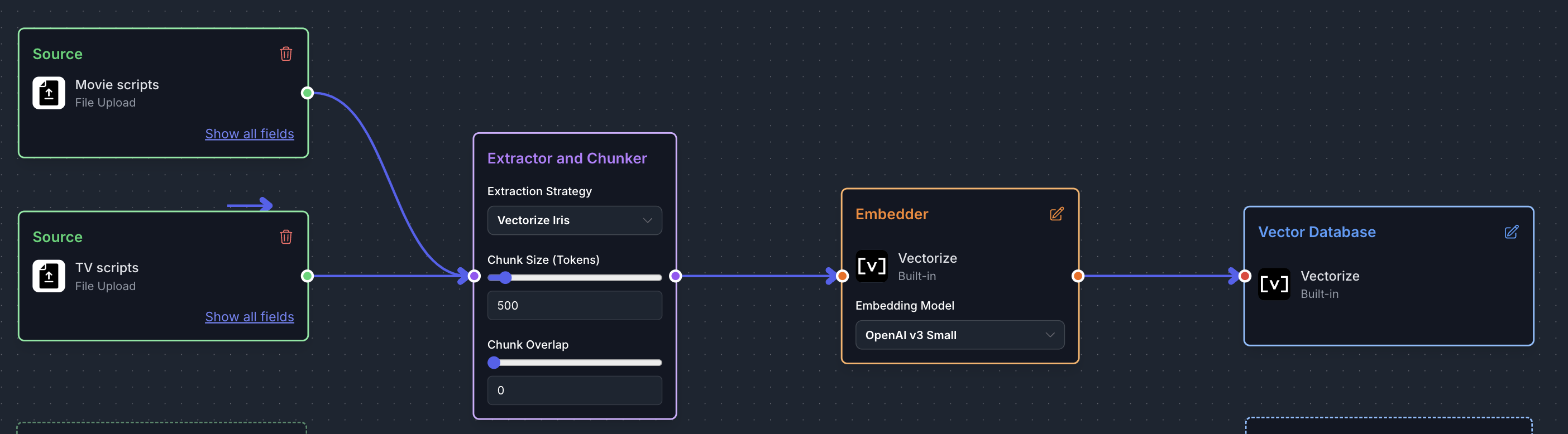
Visual RAG Pipeline Editor
We've released a completely new version of the pipeline editor. The new Visual RAG Pipeline Editor provides a cleaner, more intuitive experience, allowing you to build and deploy pipelines more efficiently. Check out our walkthrough.
Vectorize API Beta Enhancements
The API Beta continues to expand, adding more functionality for managing integrations and data pipelines. View the API docs.
Retrieval Performance
A new Retrieval Performance dashboard provides real-time monitoring and analysis of retrieval effectiveness. Learn more.
Support for Groq in our Chatbot Starter
Support for Groq has been added to the ready-to-use Next.js chatbot. The chatbot is pre-configured with your pipeline’s retrieval endpoint and can be downloaded from the Connect tab.
2025-02-03
Features
Extraction Tester
The Extraction Tester lets you test how different extraction methods process your documents before creating a data pipeline. This helps you choose the best extraction method for your specific documents and use case.
Documentation
Vectorize Iris
Vectorize Iris is a model-based extraction solution that combines extraction and chunking into one streamlined process, making it easier than ever to get clean, usable text from complex documents.
Documentation
2025-02-02
Features
Vectorize API (Beta)
Manage your connectors, AI platforms, vector databases, and pipelines using the Vectorize API. The API is Beta and may change.
Documentation
2025-01-23
Features
Query rewriting
Query rewriting uses conversation history to improve retrieval relevance. Before retrieving relevant documents, the system reformulates the user query based on the context of the conversation. This can help you provide more accurate answers to user queries.
Documentation
2025-01-16
Features
Performance metrics for data pipelines are now available in the Vectorize UI users on the Pro plan. The dashboard displays key metrics to help you evaluate retrieval performance, including:
- Non-Rewritten Relevance
- Rewritten Question Relevance
- Overall Retrieval Health
New pipeline status: HIBERNATING
If a pipeline has been inactive for 14 days (no data processed, no use of the retrieval endpoint), it will hibernate. In order to use the pipeline it must be manually restarted.
If the pipeline remains inactive after restart, after 14 days it will hibernate again.
To prevent a pipeline from hibernating:
- Perform a single retrieval on the pipeline's endpoint.
- A new document being written/updated will also prevent hibernation.
Documentation
Integrations
New Vector Database: Weaviate
Documentation
2025-01-10 🎊
New Integrations
- New Vector Databases
- Qdrant
2024-12-26
New Integrations
- New Vector Databases
- PostgreSQL
2024-12-06
Features
- Added a context recall metric to RAG evaluations, which measures whether the retrieved context contains the necessary information to answer the provided question. The higher the value, the better the system is at retrieving relevant context.
New Integrations
- New Vector Databases
- Milvus / Zilliz Cloud
2024-11-29
- Added the ability to select multiple Dropbox folders to read data from.
New Integrations
- Connectors
- SharePoint
- New AI Platforms
- Vertex AI
2024-11-21
Features
- Added support for Firecrawl's
/scrapeendpoint. - Integrations not in use by a data pipeline can now be edited.
New Integrations
- Connectors
- Firecrawl
- Google Drive
- Dropbox
- OneDrive
- New Vector Databases
- SingleStore
- New AI Platforms
- Amazon Bedrock
2024-10-31 🎃
Features
-
Connectors and AI Platforms not being used by a pipeline can now be edited.
-
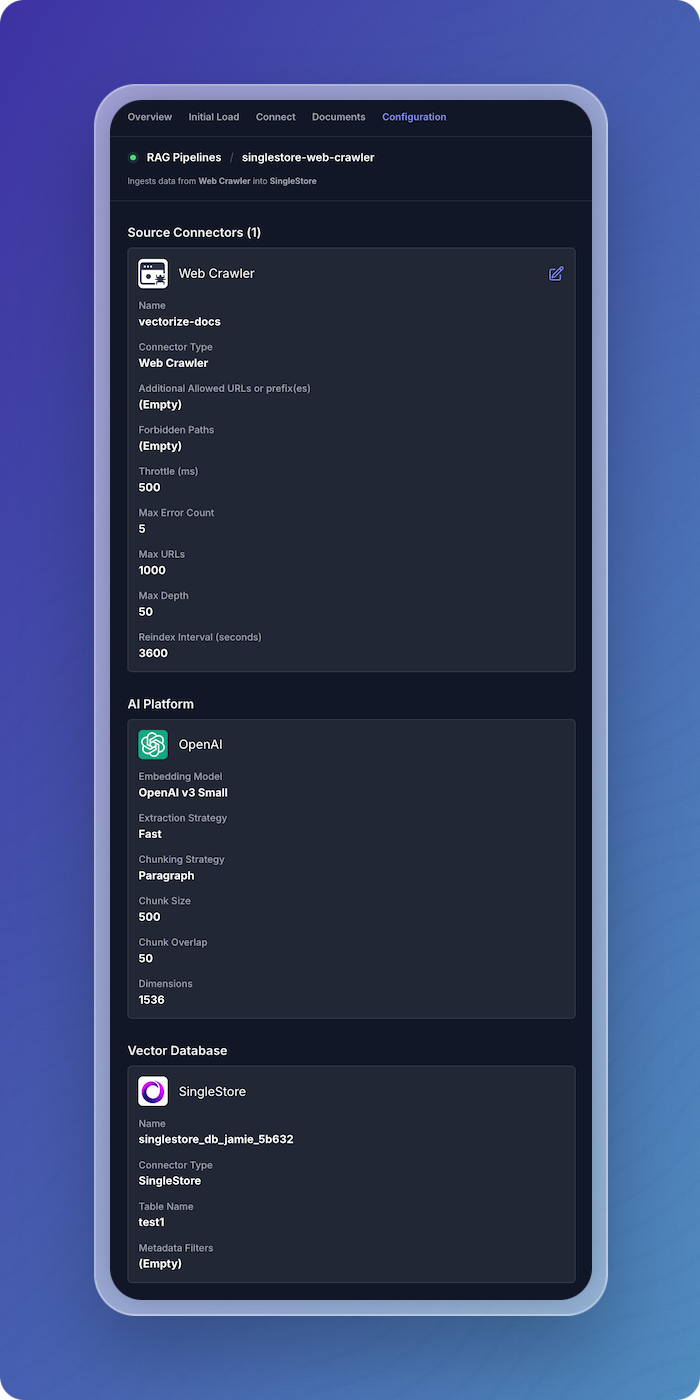
Added a tab which displays configuration for the source connector(s), AI platform, and vector database for the selected data pipeline.
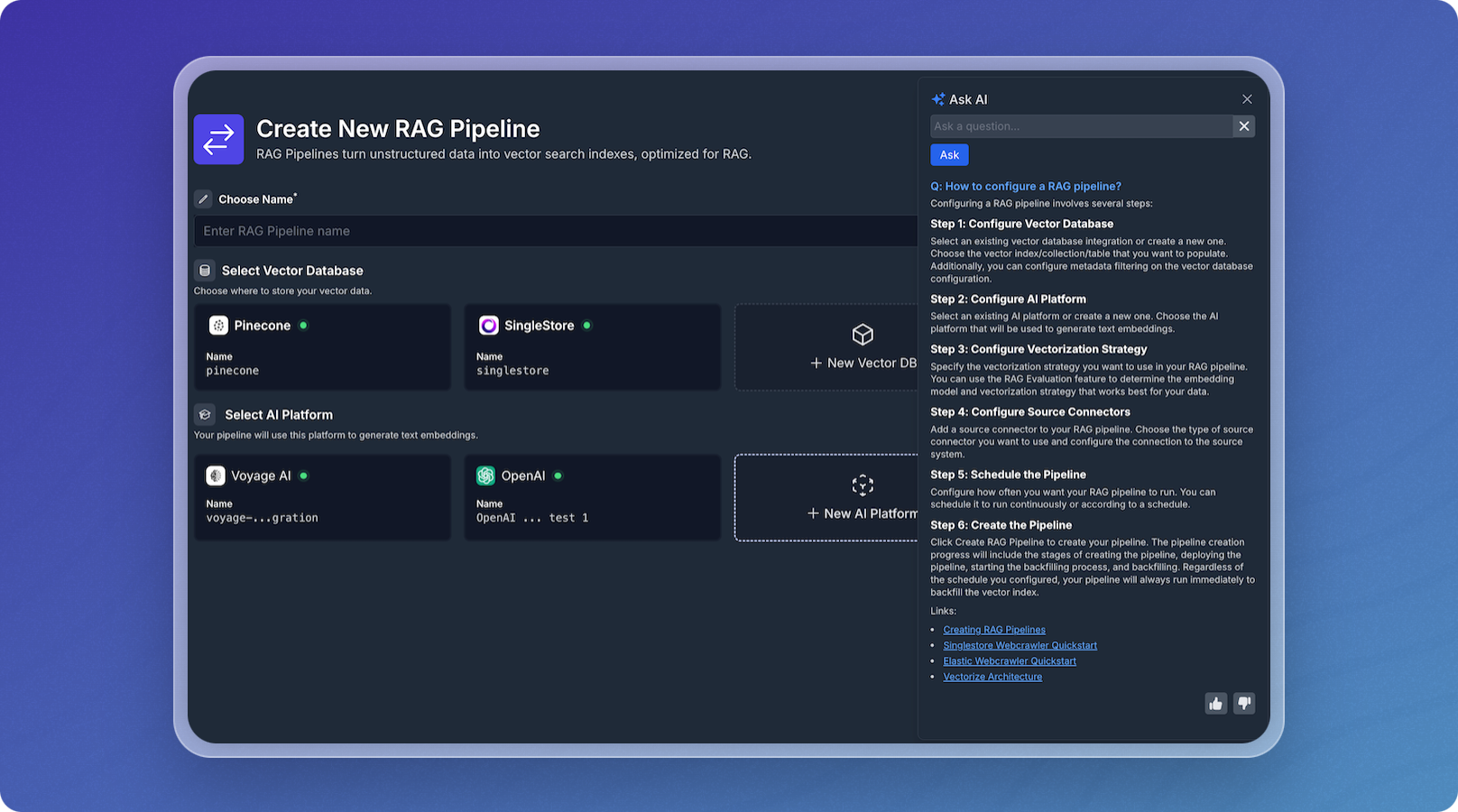
- Added an AI Assistant which will answer context-specific questions as you use Vectorize. You can optionally give the answer a thumbs-up or thumbs-down.
New Embedding Models
- voyage-3
- voyage-3-lite
- voyage-finance-2
- voyage-multilingual-2
- voyage-law-2
- voyage-code-2