Build Your First RAG Pipeline
Time to complete: 5 minutes
This quickstart will show you how to create a pipeline that:
- Ingests your documents
- Creates vector embeddings
- Makes your data searchable using AI
We'll use the Web Crawler connector as well as our built in, free to use, embedding model and vector database to process documents from your device.
Before you begin
Before you begin, you'll need:
- A Vectorize account (create one free here ↗ )
- A website you wish to crawl and index
Step 1: Create Your RAG Pipeline
-
Log in to Vectorize.
-
Click New RAG Pipeline in the left sidebar.
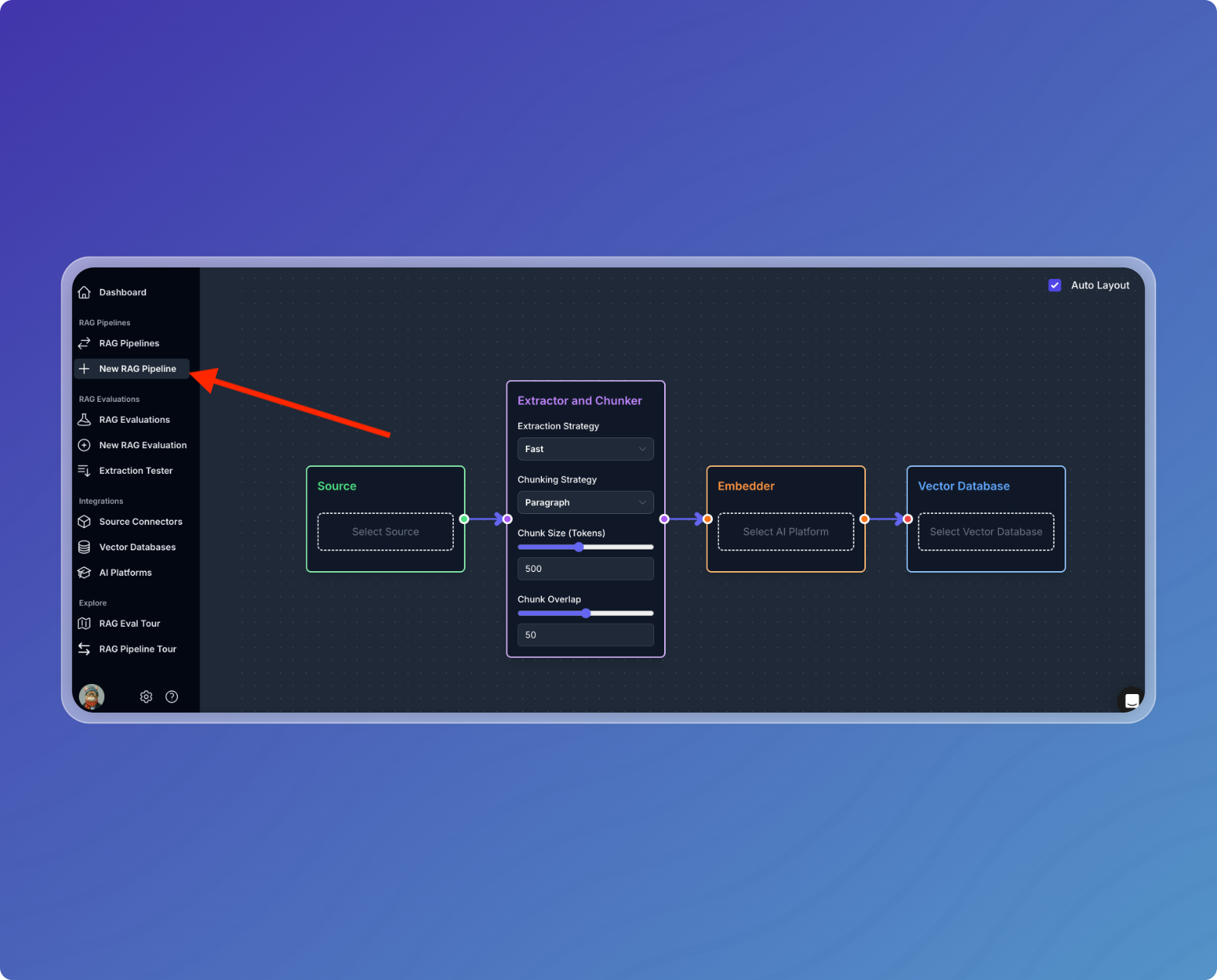
-
Name your pipeline (e.g., "Quickstart Pipeline").
-
Select your data source:
- Click Select Source.
- Choose Web Crawler.
- Enter a name for the Web Crawler.
- Enter a website you wish to crawl.
- Click Create Web Crawler Integration.
- You may wish to add additional configuration options, such as additional URLs and forbidden paths.
-
Configure your Extractor and Chunker:
- This is where you may configure the extractor and chunker for your pipeline.
- For this quickstart, we will use the default values.
-
Choose Embedder:
- For this quickstart, we will use Built-in Embedder.
- This is a free to use embedding model provided by Vectorize.
-
Choose Vector Database:
- For this quickstart, we will use Built-in Vector Database.
- This will be automatically selected so you do not need to do anything.
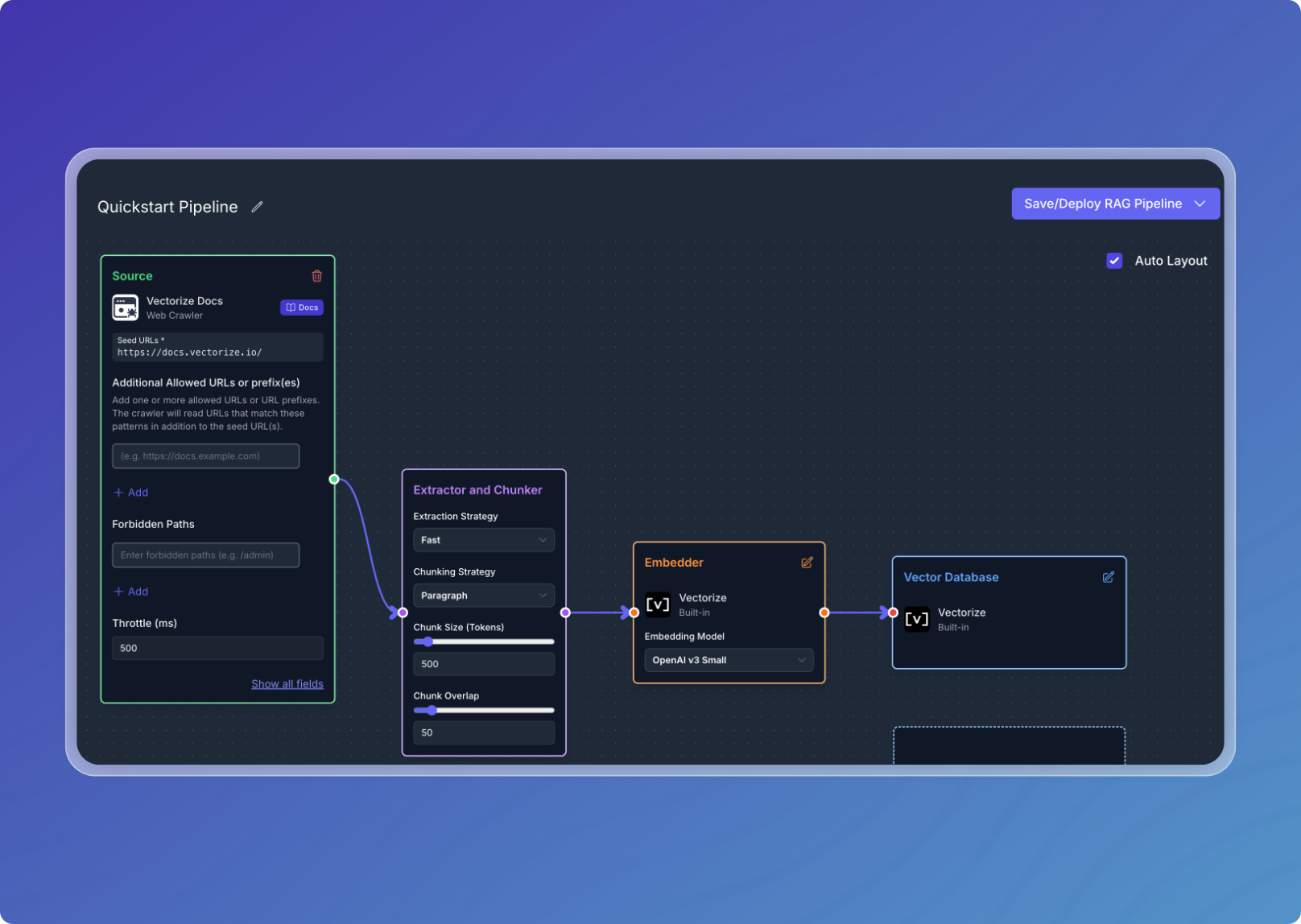
Step 2: Deploy your pipeline:
-
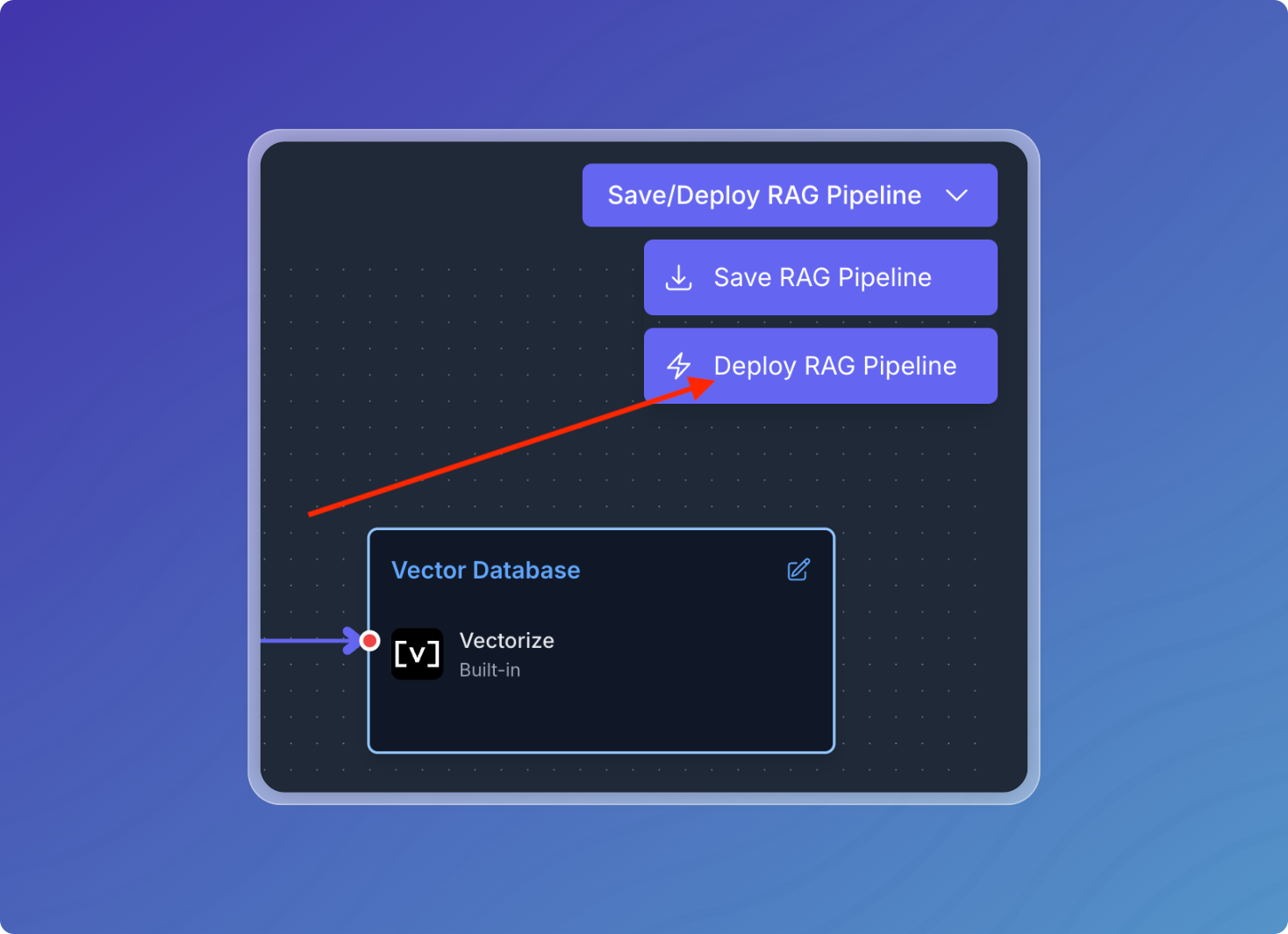
Click Save/Deploy RAG Pipeline.
-
If you wish to save your pipeline as a draft, click Save RAG Pipeline. Otherwise, click Deploy RAG Pipeline.
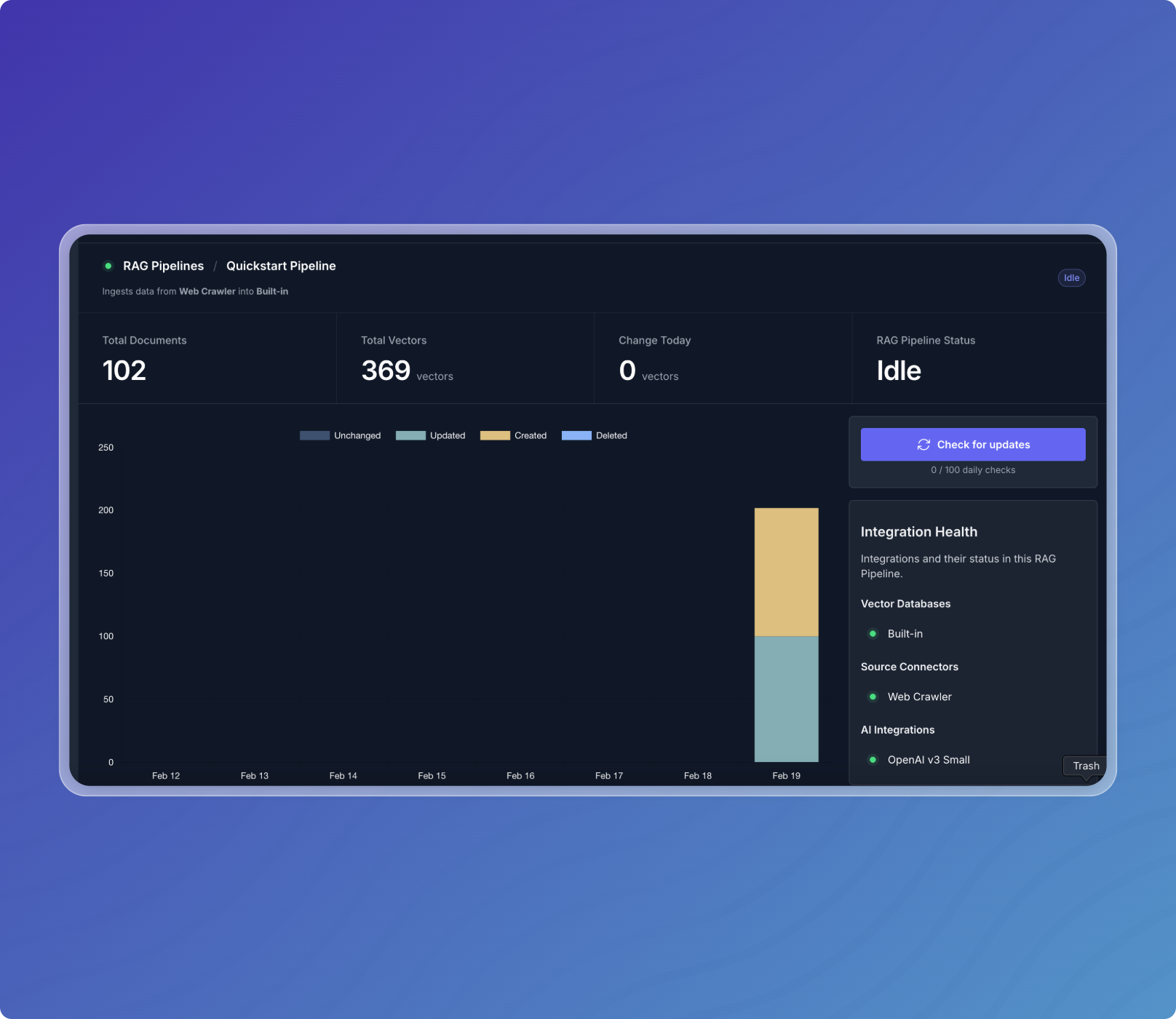
Your pipeline will crawl the website you selected, ingest the content, generate embeddings, and write them to the vector database.
When the embeddings have been stored in the database, your pipeline's status will change to the Listening state, where it will "listen" for more updates to ensure there is no more data left to process. Once it's done processing it will go into Idle state.
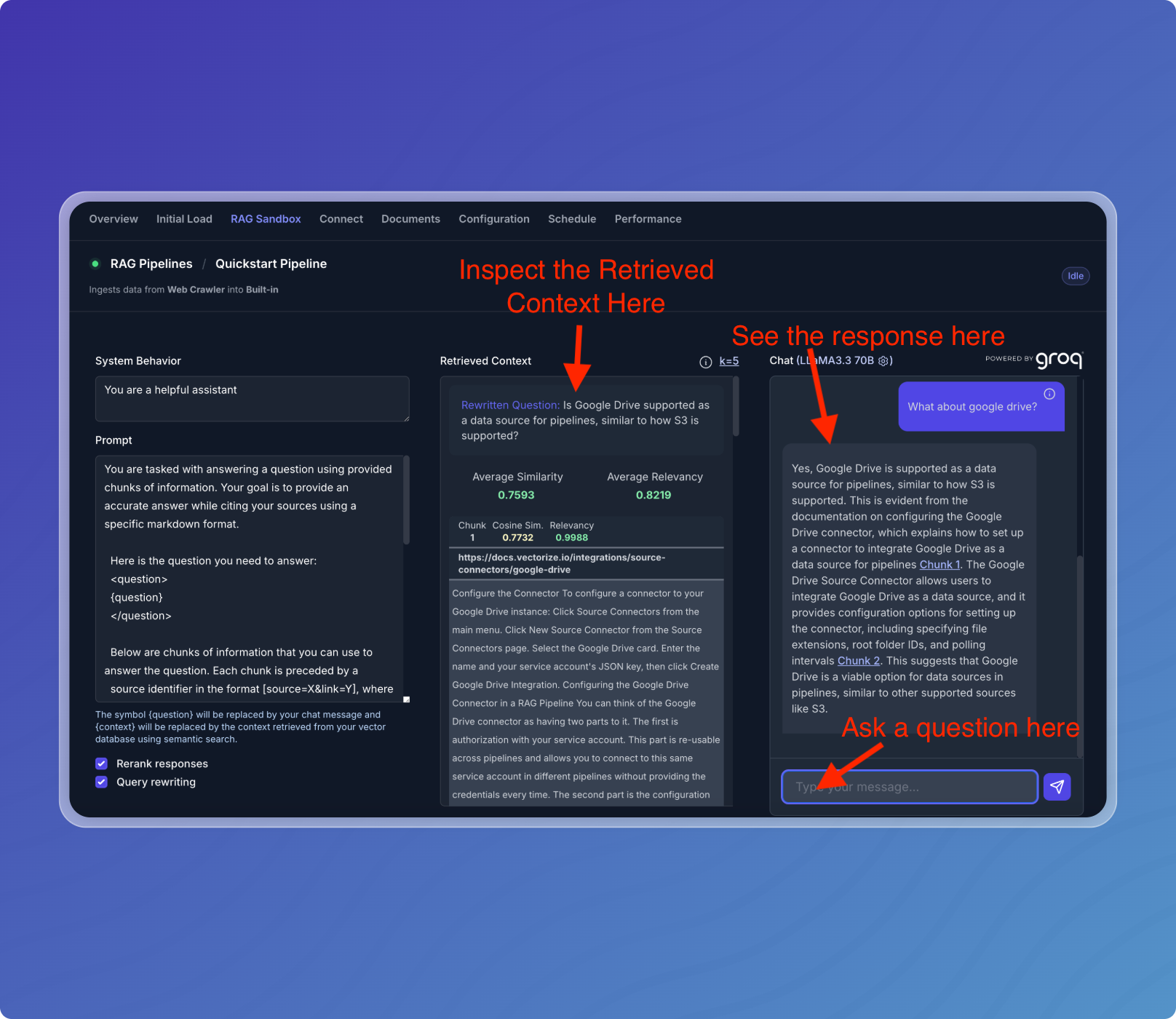
Step 3: Try it out!
- Click the RAG Sandbox tab to open the RAG Sandbox.
- Ask a question about your website.
- See your data in action!
What's Next?
- Add more documents to your pipeline: File Upload
- Connect to different data sources: Source Connectors
- Compare different embedding models: Introduction to RAG Evaluation
- Learn more about using the RAG Sandbox: Using the RAG Sandbox