Build Your First Bring Your Own Keys RAG Pipeline
Time to complete: 5 minutes
This quickstart will show you how to create a pipeline that:
- Ingests your documents
- Creates vector embeddings
- Makes your data searchable using AI
We'll use Pinecone, OpenAI, and the File Upload connector to process documents from your device.
Before you begin
Before you begin, you'll need:
- A Vectorize account (create one free here ↗ )
- An OpenAI API key
- A Pinecone API key and a Pinecone vector database
Step 1: Create Your RAG Pipeline
-
Log in to Vectorize.
-
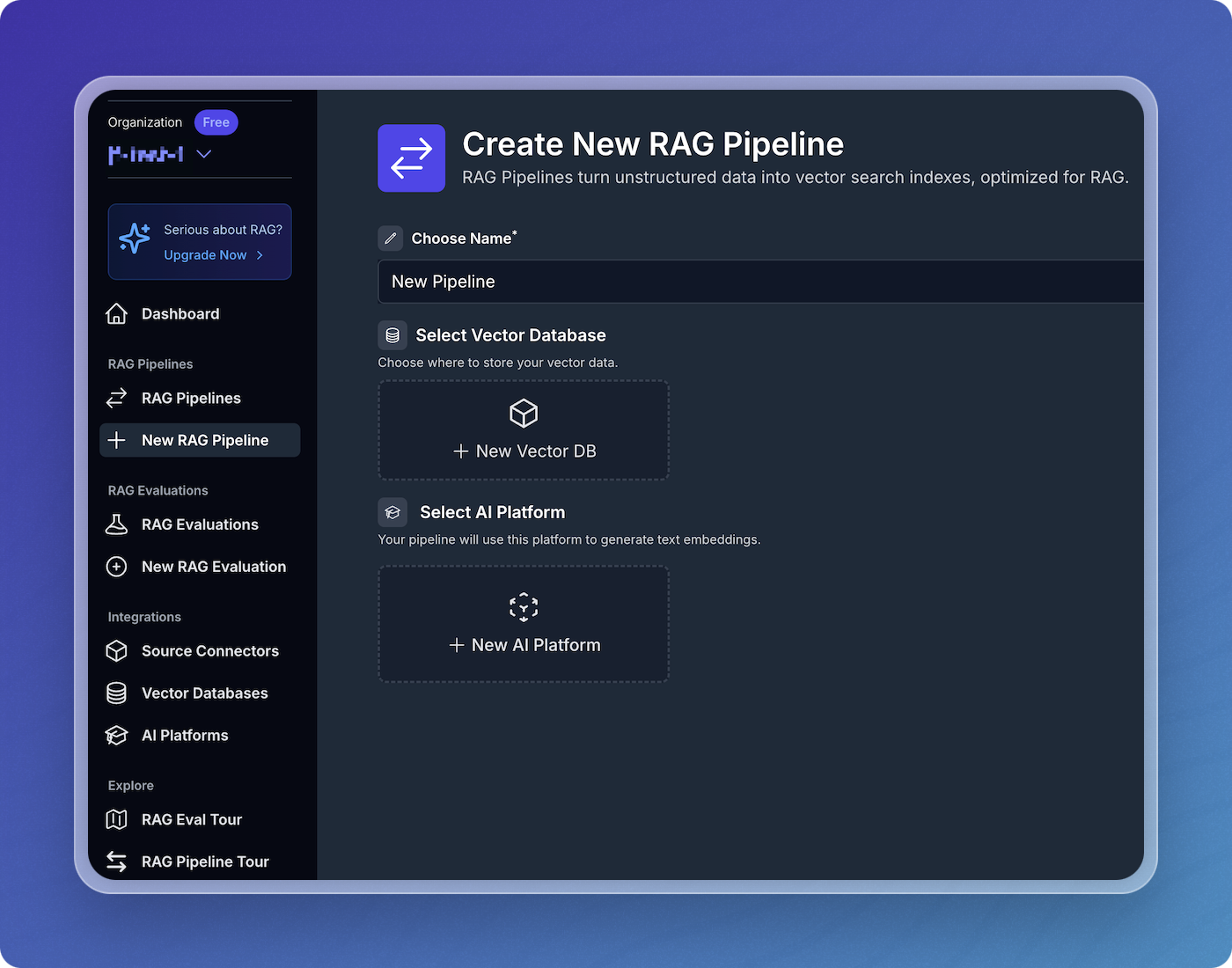
Click New RAG Pipeline in the left sidebar.
-
Name your pipeline (e.g., "quickstart-pipeline").
-
Set up your vector database:
- Click New Vector DB.
- Choose your database, and enter your credentials.
- Provide an index name (e.g., "vectorize-quickstart"). If the index does not already exist in your database, it will be created automatically.
-
Configure your AI platform:
- Click New AI Platform.
- Select your platform and enter your credentials (e.g., OpenAI API key).
- Leave the default values for embedding model and chunking.
-
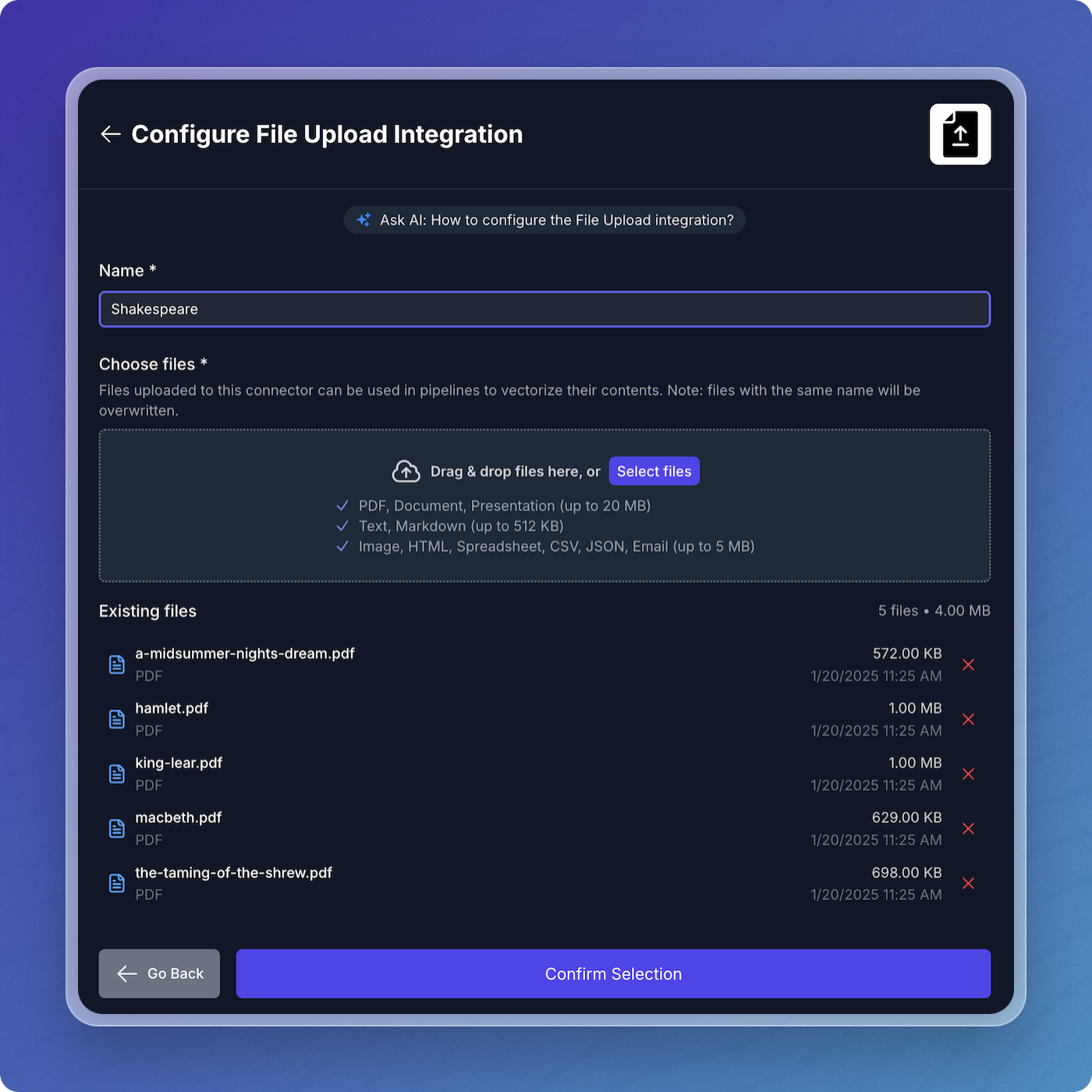
Add your data source:
- Click Add Source Connector.
- Choose File Upload.
- Upload one or more files.
- Click Confirm Selection.
Step 2: Schedule and deploy your pipeline:
-
Click Next: Schedule RAG Pipeline.
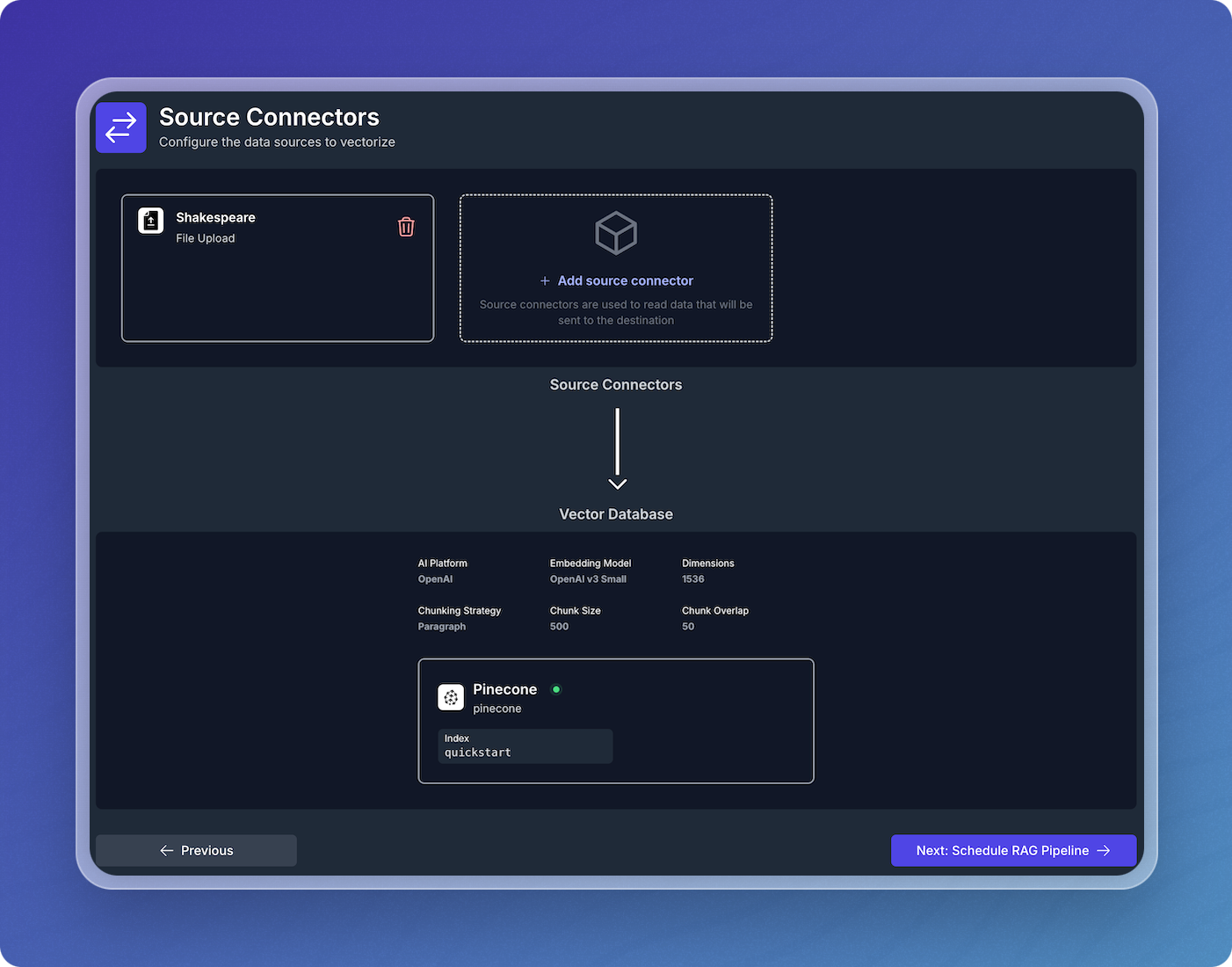
-
Accept the default schedule configuration and click Create RAG Pipeline.
Your pipeline will ingest the file(s) you selected, generate embeddings, and write them to your vector database.
When the embeddings have been stored in your database, your pipeline's status will change to the Listening state, where it will stay until more updates are available. For example, if you modify one of the files you specified when configuring the File Upload connector, the pipeline will reprocess it.
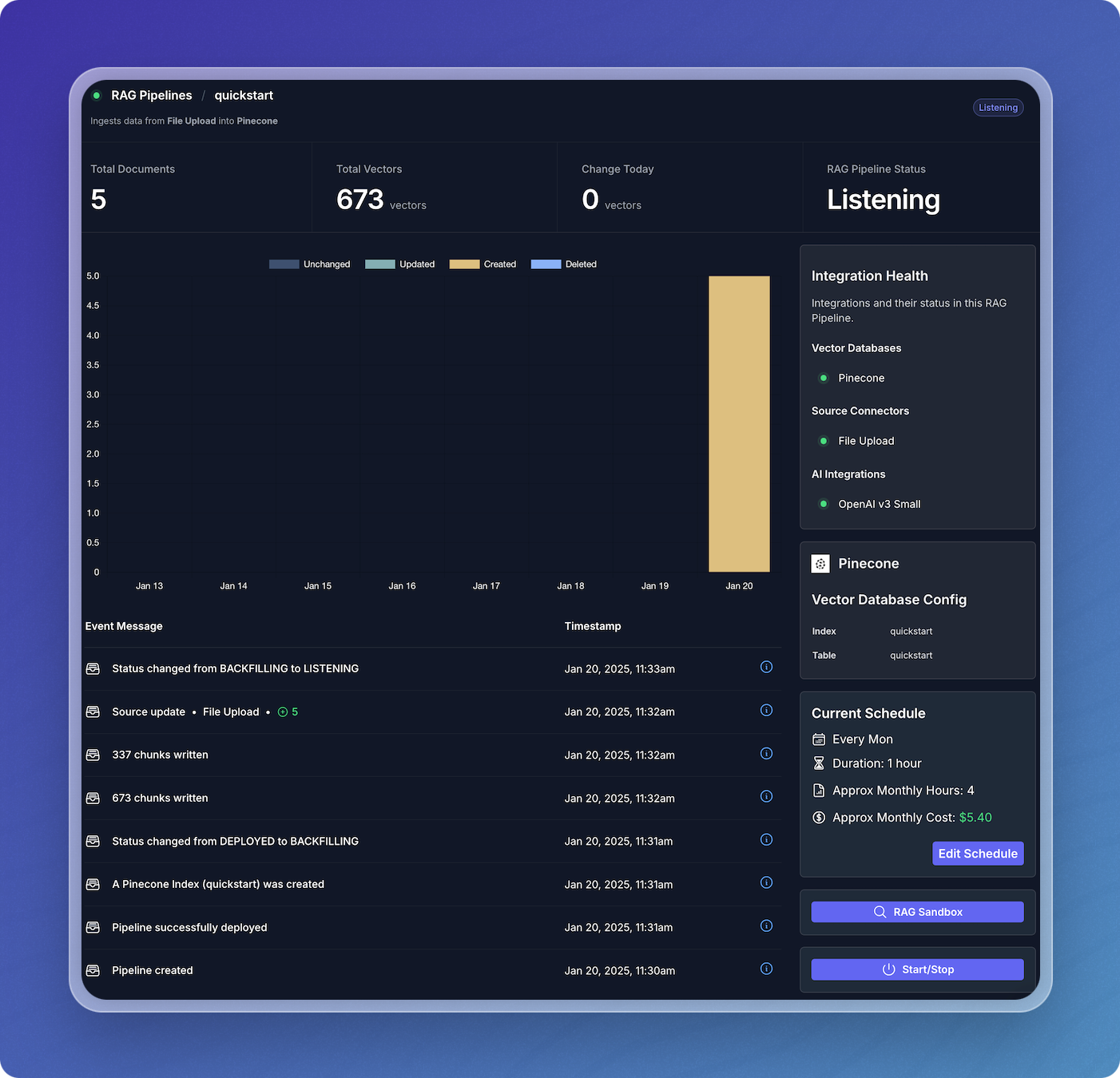
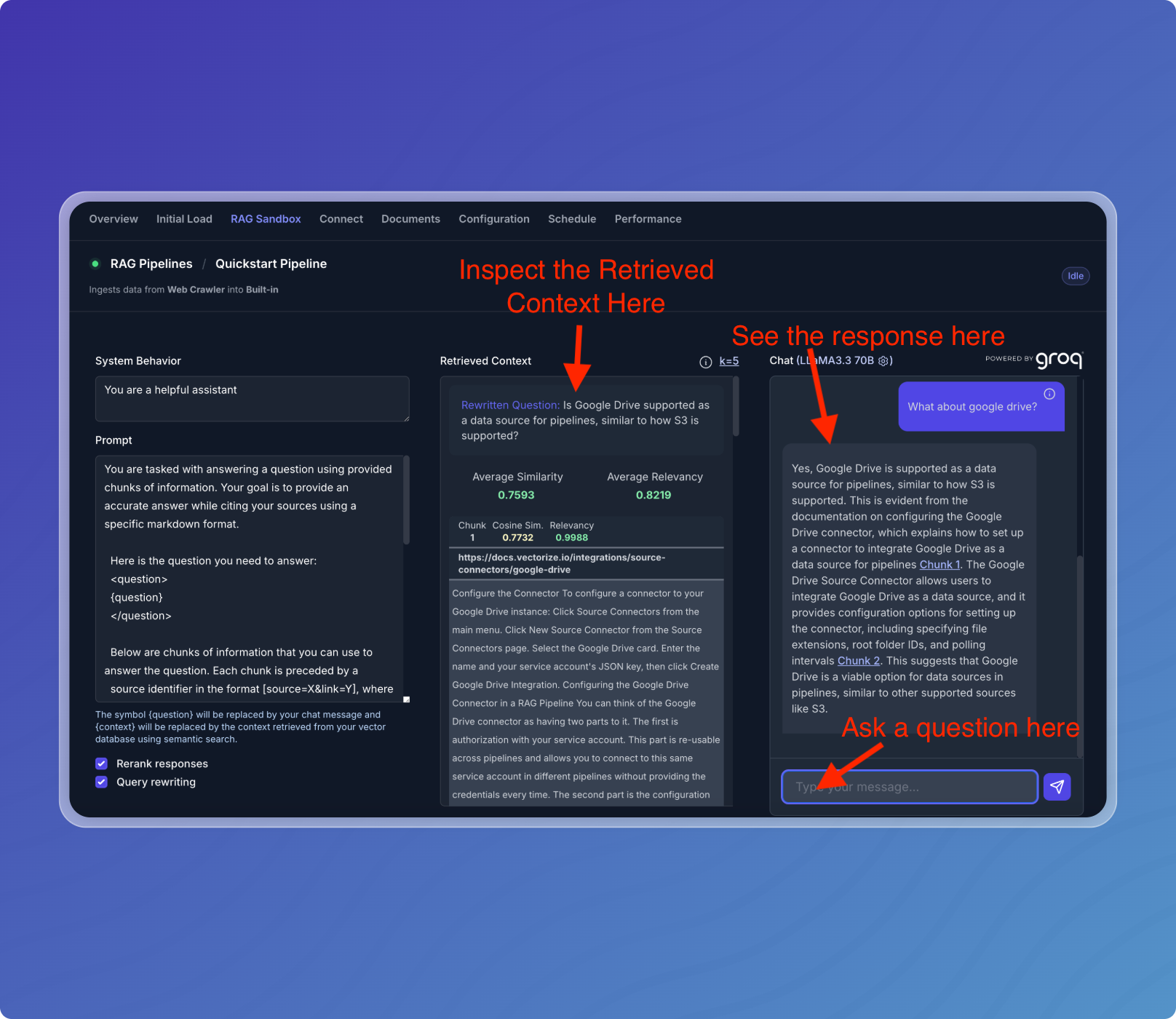
Step 3: Try it out!
- Click the magnifying glass icon to open the RAG Sandbox.
- Ask a question about your documents.
- See your data in action!
What's Next?
- Add more documents to your pipeline: File Upload
- Connect to different data sources: Source Connectors
- Compare different embedding models: Introduction to RAG Evaluation
- Learn more about using the RAG Sandbox: Using the RAG Sandbox