Intercom
RAG Pipeline Quickstart with Intercom
Transform your Intercom customer conversations into a searchable knowledge base with this quickstart guide. You'll create a pipeline that automatically ingests conversations from Intercom, generates vector embeddings using Vectorize's built-in embedder, and stores them in the integrated vector database—providing a complete RAG solution without any external dependencies.
Prerequisites
Before starting this quickstart, ensure you have:
- A Vectorize account (Sign up free ↗)
- An Intercom workspace with admin access
- At least a few conversations in your Intercom workspace to test with
Step 1: Create an Intercom Source Connector
Navigate to the New RAG Pipeline page in Vectorize to begin setting up your Intercom integration.
-
Click the Select Source button and choose Intercom from the available connectors.
-
Click Add a new Connector to create a new Intercom source connector.
-
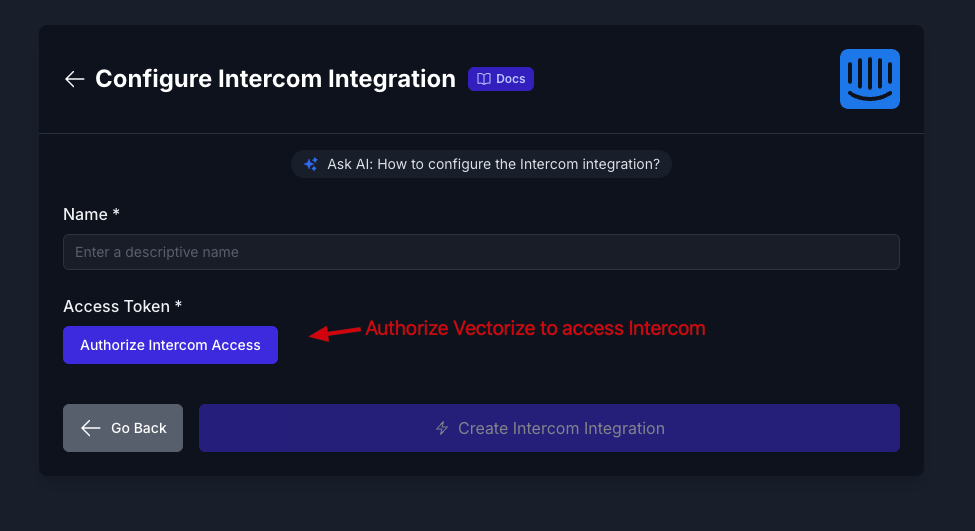
Enter a descriptive name for your connector (e.g., "Customer Support Conversations") and click Authorize to begin the OAuth authentication flow.
-
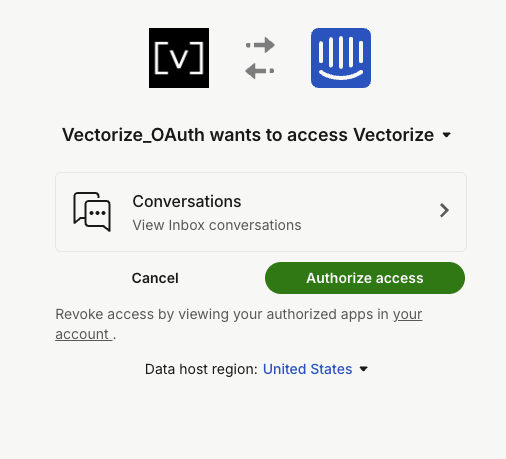
You'll be redirected to Intercom to grant permissions. After authorization, return to Vectorize and click Create Intercom Integration to save your connector.
-
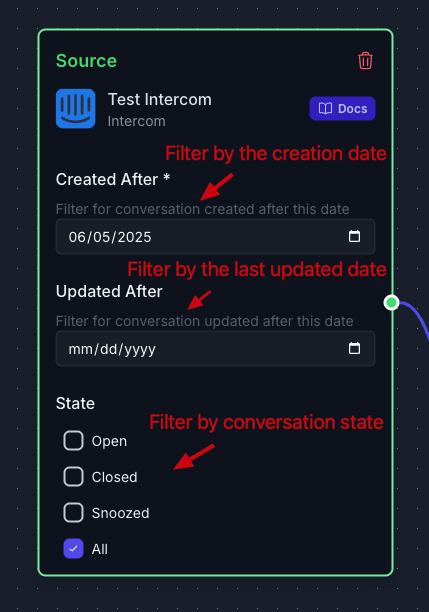
(Optional) Configure filters to refine which conversations are ingested:
- Date range: Select conversations from a specific time period
- Conversation state: Choose between open, closed, or snoozed conversations
- Tags or assignees: Filter by specific tags or team members
Step 2: Configure Your RAG Pipeline
With your Intercom connector ready, configure the pipeline settings for optimal performance.
Extraction and Chunking
For this quickstart, we'll use the default extraction and chunking strategies, which work well for most conversation data. These defaults:
- Extract text content from conversations including messages and metadata
- Create optimally-sized chunks for retrieval accuracy
Select Vectorize's Built-in AI Platform and Database
-
Click the Select AI Platform button and choose Built-in to use Vectorize's integrated embedder.
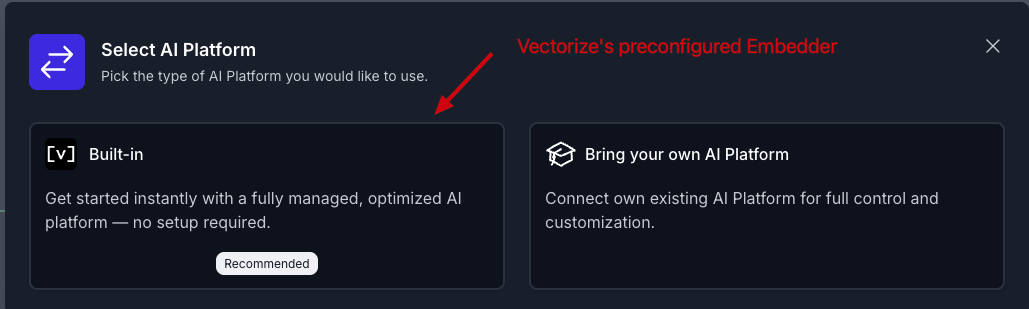
This selection automatically configures:
- Embedder: Vectorize's optimized embedding model
- Vector Database: Built-in Vectorize vector storage
Deploy Your Pipeline
-
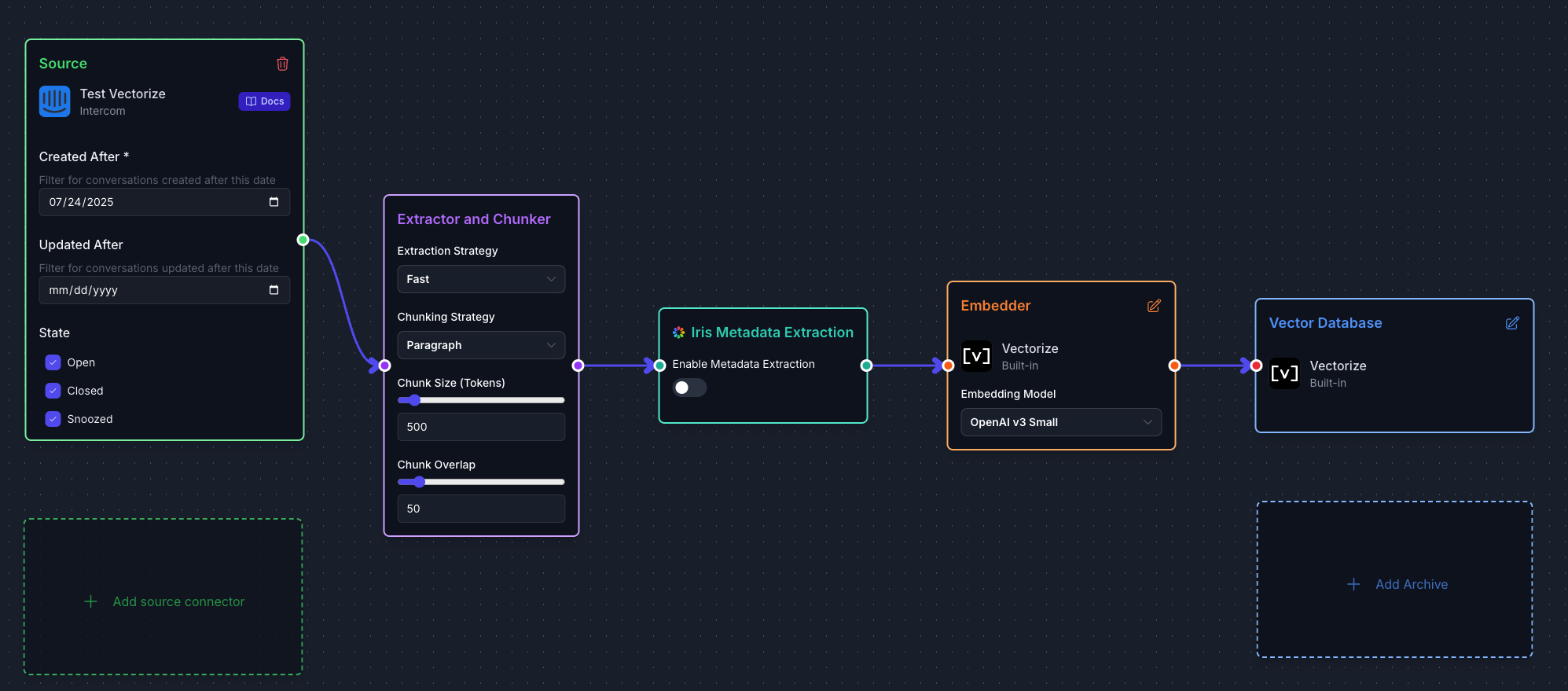
Review your pipeline configuration, which should show:
- Source: Your Intercom connector
- AI Platform: Vectorize (Built-in)
- Destination: Vectorize (Built-in) Vector Database
-
Click Deploy RAG Pipeline to create and start your pipeline.
Your pipeline will begin processing conversations immediately. Initial ingestion time depends on the volume of conversations but typically completes within a few minutes for most workspaces.
Step 3: Query Your Knowledge Base
Once your pipeline has processed the conversations, you can start querying your Intercom knowledge base.
Using the RAG Sandbox
- Navigate to RAG Sandbox in the Vectorize dashboard
- Select your Intercom pipeline from the dropdown
- Try queries like:
- "What are the most common customer issues?"
- "Show me conversations about pricing concerns"
- "What feature requests have customers mentioned?"
Using the API
Query your pipeline programmatically using the retrieval endpoint:
curl -X POST https://api.vectorize.io/v1/rag/retrieve \
-H "Authorization: Bearer YOUR_API_KEY" \
-H "Content-Type: application/json" \
-d '{
"pipeline_id": "YOUR_PIPELINE_ID",
"query": "summarize customer feedback about onboarding",
"top_k": 5
}'
What's Next?
Now that your Intercom RAG pipeline is running:
- Refine your filters: Adjust date ranges or conversation states to focus on specific customer segments
- Connect to an LLM: Use the retrieval results with ChatGPT, Claude, or other LLMs for conversational insights
- Set up monitoring: Track query performance and adjust retrieval parameters as needed
- Explore metadata: Use conversation tags and assignee information for more targeted searches
Troubleshooting
Common Issues
No conversations appearing in the pipeline:
- Verify that conversations exist in Intercom within your selected date range
- Check that the OAuth authorization completed successfully
- Ensure the conversation states (open, closed, snoozed) you selected match existing conversations in your workspace
Pipeline processing taking longer than expected:
- Large conversation volumes require more processing time—check the pipeline status for progress updates
- Review pipeline logs for any API rate limit warnings
- Consider filtering by date range to process conversations in smaller batches initially
Search results not matching expectations:
- Refine your queries to be more specific to conversation content
- Check if conversations contain the terminology you're searching for
- Expand your date range if you've limited the ingestion period
Getting Help
For additional assistance:
- Review the detailed Intercom connector documentation
- Check our troubleshooting guide
- Contact our support team for personalized help