Configuring Web Crawler Source Connector
The Web Crawler Source Connector allows you to integrate Vectorize's web crawler as a data source for your pipelines, ingesting unstructured textual content from specified web pages. This guide explains the configuration options available when setting up a Web Crawler source connector.
Before You Begin
Before starting, check if the website you plan to crawl has a robots.txt file. The presence of this file may restrict certain pages or sections from being crawled. Ensure you review the robots.txt file and respect the site's crawling rules to avoid any compliance issues.
Configuring the Connector
-
Click Source Connectors from the main menu.
-
Click New Source Connector from the Source Connectors page.
-
Select the Web Crawler card.
-
Fill in the required fields, then lick Create Web Crawler Integration.
| Field | Description | Required |
|---|---|---|
| Name | A descriptive name to identify the connector within Vectorize. | Yes |
| Seed URLs | A list of root URLs where the crawler will start the crawling process from. Click + Add to add each additional Seed URL. | Yes |
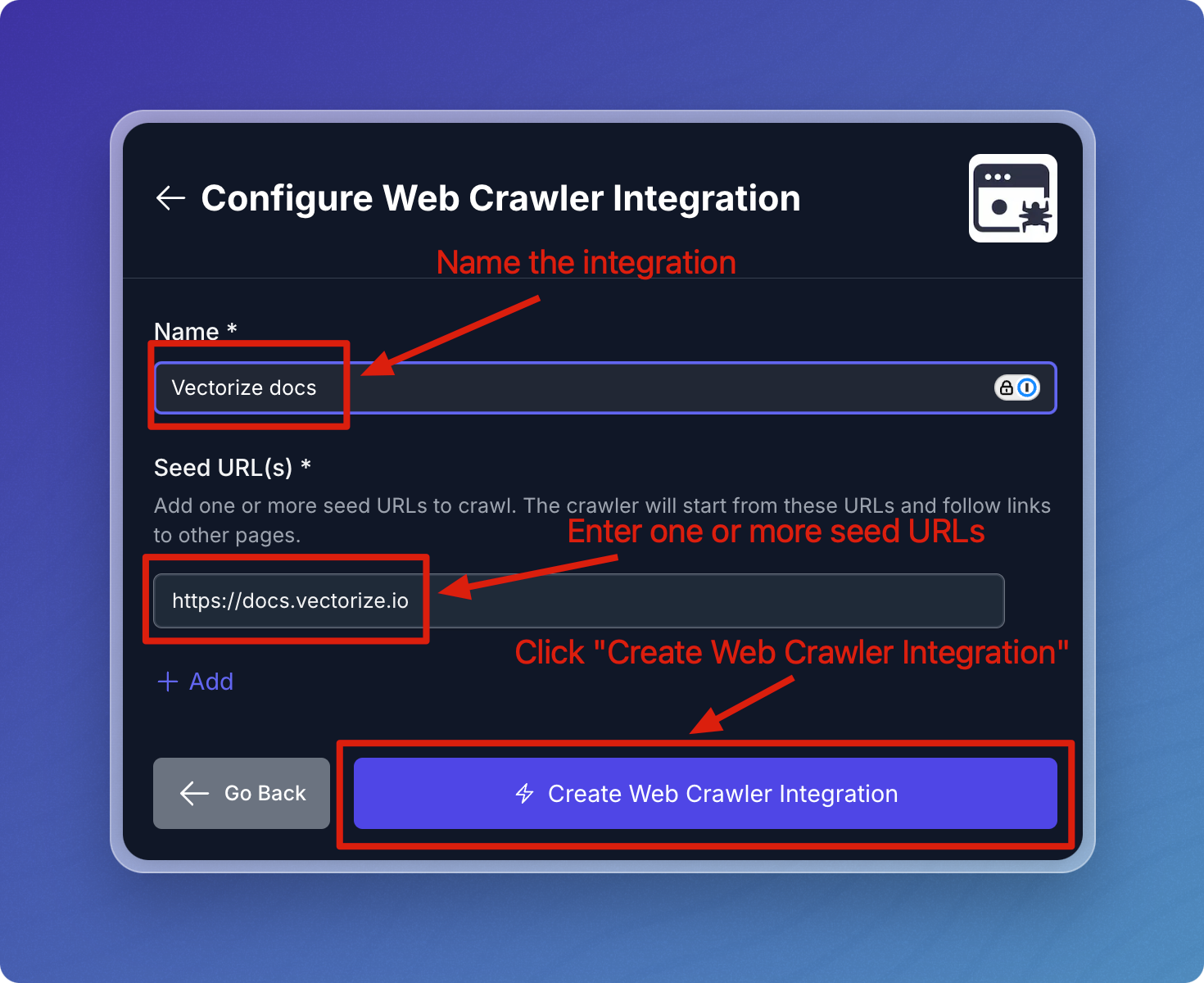
Configuring the Web Crawler Connector in a RAG Pipeline
You can think of the Web Crawler connector as having two parts to it. The first is defining the seed URL(s). This part is re-usable across pipelines and allows you to crawl the same seed URL(s) in different pipelines without having to provide the URL(s) every time.
The second part is the configuration that's specific to your RAG Pipeline. This allows you to optionally specify parameters which control what the web crawler does.
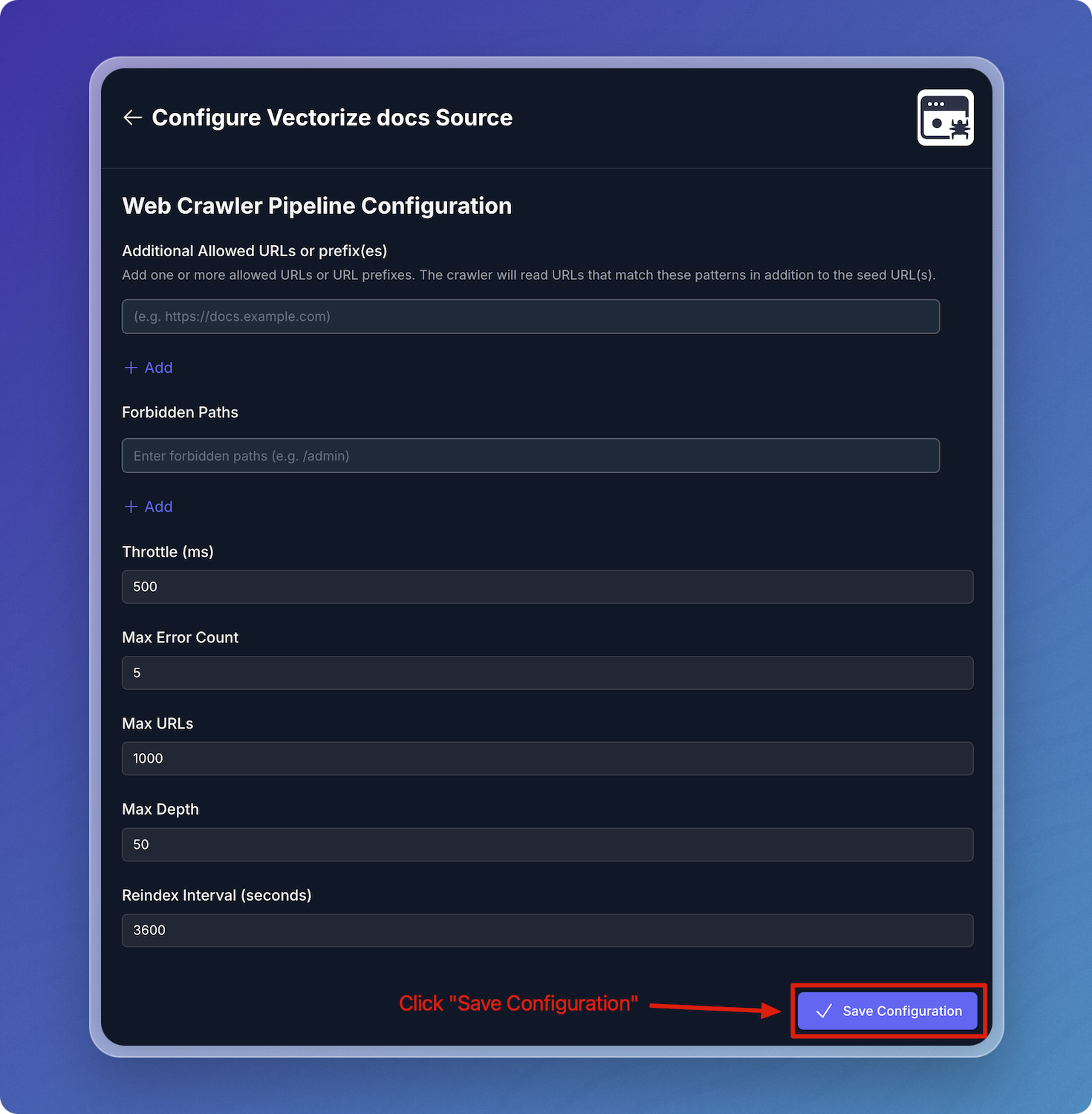
| Field | Description | Required |
|---|---|---|
| Allowed URLs | Specific URL prefixes and their subpages that are allowed to be crawled. | No |
| Forbidden Paths | Specifies paths for which the crawler should not crawl. (e.g., /admin, /login, /analytics). | No |
| Throttle (ms) | Minimum time between two requests to the same domain. | Yes |
| Max Error Count | Maximum number of errors allowed before stopping. | Yes |
| Max URLs | Maximum number of URLs that can be crawled. | Yes |
| Max Depth | Maximum depth of the crawl, beggining from the seed URL. | Yes |
| Reindex Interval (s) | How often the crawler will recrawl the pages. | No |
Usage Guidelines
Additional Allowed URLs or prefix(es): By default, the crawler will crawl pages it finds on the seed URLs. If you want the crawler to read pages it discovers outside those URLs, you can add them to this list.
A common case is when you want to crawl a main web site and its associated docs site which is on a different domain (assuming the main site has a link to the docs site for the crawler to follow). In this case, you would enter the docs site URL as an additional allowed URL. For example, your seed URL might be https://vectorize.io and your allowed URL might be https://docs.vectorize.io.
You can also use this settting restrict the crawler to specific URLs and their subpages. This helps in focusing the crawl and avoiding unnecessary content. For example, your seed URL might be https://docs.vectorize.io, and the allowed URL might be https://docs.vectorize.io/integrations. This will crawl the integrations section of the site and all its subpages, but not other pages on the site. Note there must be a link from https://docs.vectorize.io to https://docs.vectorize.io/integrations for the crawler to discover it.
Understanding Pipeline-Specific Configuration Properties for the Web Crawler
Reindex Interval(s)
- Description: The time interval (in seconds) at which the crawler will recrawl the pages. This setting is useful for keeping the data fresh and up-to-date.
- Behavior:
- If you set the interval to a low value (e.g., 120 seconds), the crawler will recrawl the pages every 2 minutes and will update the data in the vector database.
- If you do not want the crawler to recrawl the pages, set the interval to a high value (e.g., 86400 seconds for once a day).
Additional Allowed URLs or prefix(es)
-
Decription: By default, the crawler will crawl pages it finds on the seed URLs. This setting allows other URLs to be crawled or restricts crawling to specific areas of a website. Pages need to start with the seed URLs or allowed URLs to be eligible for reading.
-
Behavior:
- If you want the crawler to read pages it discovers outside those URLs, you can add them to this list.
- A common case is when you want to crawl a main web site and its associated docs site which is on a different domain (assuming the main site has a link to the docs site for the crawler to follow). In this case, you would enter the docs site URL as an additional allowed URL. For example, your seed URL might be https://vectorize.io and your allowed URL might be https://docs.vectorize.io.
- You can also use this settting restrict the crawler to specific URLs and their subpages. This helps in focusing the crawl and avoiding unnecessary content. For example, your seed URL might be https://docs.vectorize.io, and the allowed URL might be https://docs.vectorize.io/integrations. This will crawl the integrations section of the site and all its subpages, but not other pages on the site. Note there must be a link from https://docs.vectorize.io to https://docs.vectorize.io/integrations for the crawler to discover it.
Best Practices
- Start with a limited set of Seed URLs to test the crawler's behavior.
- Use Allowed URLs and Forbidden Paths to create a focused crawl, especially for large websites.
- Match sure you have permission to crawl the site. The crawler will respect any robots.txt files it finds which means it may not crawl some sites.
- If you maintain the robots.txt file on a site, allow the vectorize.io user agent to crawl the site.
- Monitor the crawl process to ensure you're getting the desired content.
Troubleshooting
If you encounter issues while creating or using the integration:
- Verify that your Seed URLs are accessible and correct.
- Ensure that Allowed URLs are properly formatted and include all necessary subdomains or paths.
- Check if the target websites have any crawling restrictions.
For further assistance, please contact Vectorize support.
Handling Unchanged Pages
To optimize resource usage and reduce unnecessary processing, the Vectorize Web Crawler includes a built-in change detection mechanism. This ensures that only modified pages are reprocessed during scheduled crawls.
Change Detection Mechanism
- Content Hashing: When the crawler initially processes a page, it computes a hash of the page's content. This hash is stored for future reference.
- Comparison on Re-crawl: During subsequent crawls, the crawler computes a new hash for each page and compares it to the previously stored hash. If the hashes match, indicating no change in content, the page is skipped.
- Selective Reprocessing: Only pages with differing hashes (i.e., changed content) are reprocessed, which includes re-embedding and re-indexing.
Configuration
- Default Behavior: By default, the crawler is configured to process only pages that have changed since the last crawl.
- Reindex Interval: The reindex-interval-seconds parameter allows you to set how frequently the crawler checks for updates. Adjusting this interval can help balance between data freshness and resource utilization.
Cost Efficiency
- Embedding Costs: Since unchanged pages are not reprocessed, there are no additional embedding costs associated with them. This approach ensures that resources are allocated efficiently, especially when dealing with large documentation sites.
What's next?
-
If you haven't yet built a connector to your vector database, go to Configuring Vector Database Connectors and select the platform you prefer to use for storing output vectors.
OR
-
If you're ready to start producing vector embeddings from your input data, head to Pipeline Basics. Select your new connector as the data source to use it in your pipeline.